Spine Swarm Hits #1 on GAIA Level 3 and Google DeepMind DeepSearchQA
How Spine’s Multi-Agent Architecture Achieved State-of-the-Art on the Hardest AI Benchmarks
By Spine AI
This week we announced that Spine Swarms became state of the art (SOTA) on the two hardest benchmarks for evaluating General AI Assistants on solving real world problems – GAIA Level 3 and DeepMind’s DeepSearchQA.
At the core of these results is a new paradigm for multi-agent orchestration — one that goes beyond how agents communicate and coordinate. Three advances work together to make this possible:
Canvas and block-based workspace — Unlike static file systems, Spine’s workspace is an infinite canvas built around intelligent, agentic blocks — discrete units that can browse the web, generate slide decks, produce images, and more. Blocks connect to one another on the canvas, passing context from parent to child, allowing multiple agents to work on different aspects of the same data simultaneously. The result is a shared environment that mirrors the way humans actually think: non-linear, composable, and structured around the shape of the problem.
Multi-agent orchestration — A central orchestrating agent decomposes complex tasks into subtasks, delegating each to specialized persona agents optimized for that type of work. Structured handoff methods — both on the canvas and between agents — ensure context is passed cleanly at each transition. For long-running tasks, context compaction prevents information loss as context windows grow.
Task-optimized model selection — Rather than relying on a single model, Spine Swarm dynamically selects the best model — or ensemble of models — from a pool of 300+ for each task.
Together, these mechanisms allow Spine Swarm to run coherently and autonomously over several hours, generalizing across benchmark complexity and the unpredictability of real-world tasks.
This post starts with the benchmarks themselves — what makes them a meaningful proxy for real-world performance, our results and why reaching #1 on both is significant. We then go deep on the architecture behind these results: the orchestration, workspace, and model selection decisions that make it work, and why together they represent a fundamentally new approach to building AI agents that perform beyond the lab.
The Benchmarks and Our Results
Before diving into the architecture, it’s worth establishing why these particular benchmarks are a meaningful proxy for real-world performance — and why reaching #1 on both is hard.
GAIA Level 3 — Real-World Agency
GAIA is widely regarded as the gold standard for evaluating AI agents on real-world tasks. Originally developed by researchers at Meta AI, Hugging Face, and AutoGPT, it consists of over 450 non-trivial questions with unambiguous, verifiable answers. Unlike traditional academic benchmarks that test narrow capabilities in isolation, GAIA tests whether AI systems can actually do things in the real world.
The benchmark has three levels of increasing difficulty:
Level 1 — Solvable by very capable LLMs
Level 2 — Requires proficient tool use and multi-step reasoning
Level 3 — Demands the integration of web browsing, code execution, multi-modal understanding, and extended reasoning chains across heterogeneous data sources. Every question is graded on exact correctness with no partial credit. A single reasoning error anywhere in the chain produces a wrong answer.
Humans score 92% on GAIA overall. On Level 3 specifically, even the most advanced AI systems with full tool access struggle significantly. This is the tier that separates agents that can follow instructions from agents that can genuinely reason, plan, and execute in complex environments.
Our results:
We report two numbers. The first — 61.5% — is our score on the validation set as-is. We report on the validation set because that is what Manus, OpenAI, and Genspark used, making the comparison apples-to-apples. This score alone is enough to rank #1. The second — 76.0% — accounts for questions in the dataset that are ambiguous or mislabeled, which we document in detail below. We include both in the interest of full transparency.
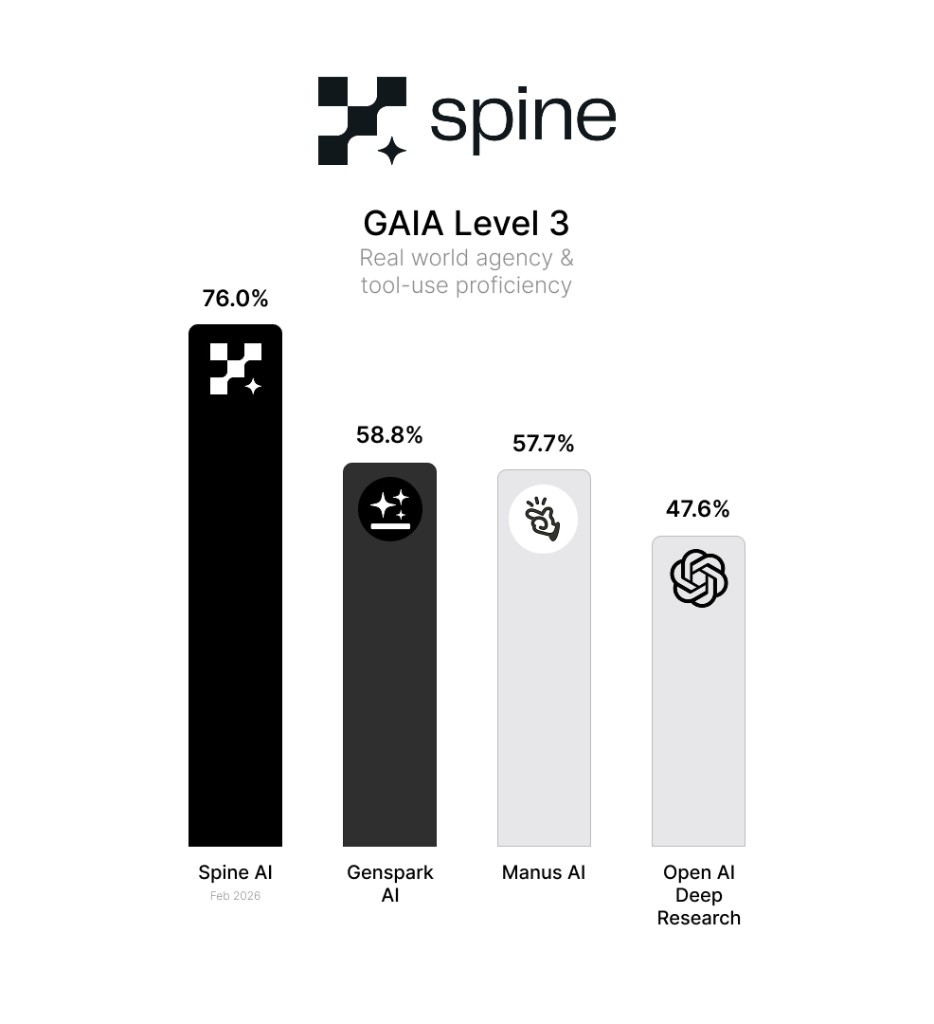
One additional note: Genspark reports a score of 58.8% — which warrants scrutiny, given that GAIA grades on exact correctness with no partial credit. A score like this should resolve to a clean fraction with the total number of questions as the denominator. We flag this not to be combative, but because benchmark integrity matters to the community that relies on these numbers.
A Note on the Dataset
GAIA is an excellent benchmark, but running it at scale in 2026 surfaces some nuances worth documenting.
Methodology
Many GAIA questions reference information that has changed since the dataset was compiled. To handle this, we instructed our agents to assume the year is 2024 — and if information wasn’t available on the current web, to fall back to the web archive. Without this, a significant number of questions would be unanswerable through no fault of the agent. This is also why we limited our run to Level 3 rather than reporting across all levels.
Mislabeled and Ambiguous Questions
A small number of questions in the dataset appear to be ambiguous or mislabeled. Two examples worth calling out:
Excel COUNTIFS question — The question asks agents to count bills shorter than 42mm using a spreadsheet. The grader’s answer uses
COUNTIFS(C1:C345, ">42"), which counts bills longer than 42mm. The question asks for shorter. Regardless of how the question is interpreted, the grader’s approach produces the wrong result (canvas).Claude Shannon — The question asks which scientist in the 1960s documentary The Thinking Machine predicted the soonest arrival of thinking machines. The benchmark marks Claude Shannon as correct — but Shannon predicted 10-15 years. Jerome Wiesner predicted 4-5 years. The benchmark had the wrong answer (canvas).
We raise these not to dispute our results — we are #1 either way — but because intellectual honesty about benchmark limitations is part of what makes benchmark results meaningful. The AI agent community benefits from a clear-eyed view of where GAIA is reliable and where it isn’t.
Transparency and Auditability
Most agent benchmarks produce a number. Spine Swarm produces a number you can verify. Because agents do their work on the canvas, every step of every task is logged, inspectable, and auditable — you can trace exactly how the agent arrived at its answer, where it searched, and what it reasoned. This applies equally to our GAIA and DeepSearchQA results. We cover this in detail — with full canvas walkthroughs for both benchmarks — in the Supporting Evidence section below.
Google DeepMind DeepSearchQA — Multi-Step Research
DeepSearchQA is a 900-prompt benchmark released by Google DeepMind alongside their upgraded Gemini Deep Research agent — designed to evaluate performance on the most demanding form of information work: multi-step research requiring sustained reasoning across extended sessions.
Unlike benchmarks that test isolated question-answering, DeepSearchQA presents hand-crafted causal chain tasks across 17 fields, where each step in the reasoning process depends directly on the analysis from the prior step. The benchmark specifically tests capabilities that break most current agent systems: gathering fragmented information across disparate sources, resolving conflicting data points, knowing when to stop searching, and maintaining coherent execution plans across long research horizons. Answers are evaluated purely on outcome — completeness and correctness of the final response — regardless of the search trajectory used to get there.
Our results:
Spine Swarm achieved 87.6% on DeepSearchQA — ranking #1 on the full 900-sample benchmark, ahead of Perplexity by 8.1% and ahead of Google’s own Gemini Deep Research by 21.5%.
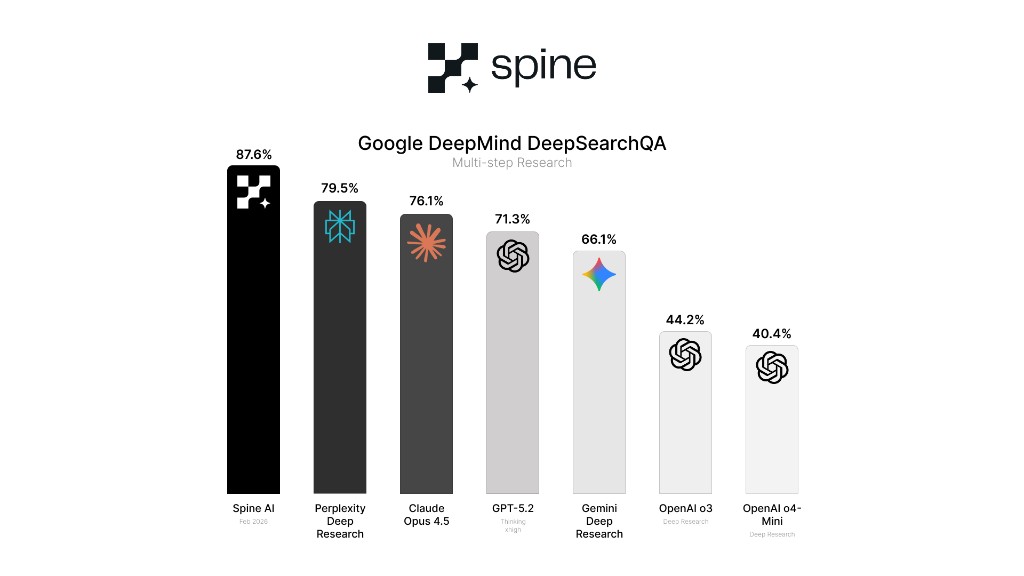
One important methodological note: we report “fully correct” scores across the entire 900-sample dataset — not a subset. This matters. Reporting on subsets is a common way benchmark numbers get inflated, and a technical audience should know exactly what they’re looking at. Our 87.6% is the hardest version of this number to achieve.
Transparency and Auditability
As with GAIA, every DeepSearchQA result is fully auditable on the canvas. We cover this — with full canvas walkthroughs for both benchmarks — in the Supporting Evidence section below.
The architecture behind the results
The scores above don’t come from a single breakthrough — they come from three advances working together. Each one addresses a different failure mode that limits current agent systems: where they work, how they coordinate, and what they reason with.
What follows is a deep dive into each.
1. The Canvas and Block-Based Workspace
Most agent systems run on file systems. Agents read files, write files. That’s their memory. It works for simple, linear tasks — but it breaks the moment complexity compounds. When you need multiple agents working in parallel, exploring different branches of a problem, or building on each other’s work, a flat file system becomes a bottleneck. There’s no native concept of structure, relationship, or parallelism. Agents end up stepping on each other, losing context, or producing outputs with no coherent relationship to one another.
Spine’s workspace was built to solve this.
An Infinite Canvas of Intelligent Blocks
Rather than files, work lives in blocks — discrete, intelligent units arranged on an infinite canvas. Each block has a type, a purpose, and a context. Blocks connect to one another, passing context from parent to child. A single web page block, for example, can feed into multiple prompt blocks simultaneously, each extracting different information from the same source. A research branch can fork in any direction. Work queues up naturally, in parallel, without collision.
We’ve handled all of the infrastructure that makes this seamless — context passing across every block type, a dependency graph that determines execution order, parallelism, and concurrency across connected blocks, and context propagation logic that handles long branches of connected blocks and the wide variance in context sizes across different block types. At benchmark scale, this infrastructure is what keeps the workload coherent and consistent across hundreds of simultaneous tasks. The hairy parts are invisible to the agent, and to the user.
Blocks on the canvas fall into five categories — AI Outputs, Artifact Builders, Data & Source Ingestion, Agentic/Execution, and User/Agent Annotation — each serving a distinct role in the pipeline. See the Appendix below for a full breakdown.
For the GAIA and DeepSearchQA benchmarks, we used a focused subset of these block types — removing all artifact builders. The results above were achieved without slides, documents, images, or apps. Those block types exist for real-world workflows, not benchmarks.
Built for Humans First — Which Turns Out to Be Good for Agents Too
The canvas wasn’t designed with benchmarks in mind. It was designed for humans — specifically, for the way humans actually think when working through complex problems: non-linearly, in parallel, with the ability to explore multiple directions at once and zoom out to see the whole picture.
What we discovered is that what’s good for humans is also good for agents. The same properties that make the canvas legible to a person — structured context, explicit relationships between blocks, visible branching — are exactly the properties that make it a reliable workspace for agents. Agents aren’t guessing at the structure of a problem from a pile of files. They’re operating in an environment that mirrors the shape of the work itself.
This also has a meaningful side effect: full transparency. Every block, every connection, every output is visible on the canvas. There’s no black box. When an agent produces a result, you can see exactly how it got there — which is both a better user experience and, as it turns out, a better way to build trustworthy AI systems.
2. Task Decomposition and Multi-Agent Coordination
A capable model running in a loop with chain-of-thought reasoning can get you far — but there is a ceiling. Pushing beyond it doesn’t just require a better model; it requires a better harness. One that can decompose problems across specialized agents running in parallel, coordinate dependencies so agents wait on and build from each other’s work, validate outputs through cross-agent review, and sustain coherent execution across long time horizons without losing context. This is what the orchestration layer was built to do.
A Three-Tiered Agent Architecture
Spine Swarm is organized around three tiers of agents, each with a distinct role:
At the top sits the orchestrating agent — responsible for decomposing a complex task into a structured set of subtasks, determining the persona agents best suited to each, mapping dependencies between them, and delegating work accordingly. Persona agents with no dependencies on each other run in parallel; those that depend on upstream outputs wait until those results are resolved. Once all subtasks are complete, the orchestrating agent synthesizes the outputs into a final response. The orchestrator doesn’t execute work directly. Its job is to plan, sequence, delegate, validate, and close.
Below it are the specialized persona agents — each optimized for a specific type of work. A persona agent might be a researcher, an analyst, a synthesizer, or a writer. Each one operates on the canvas using the intelligent block system described above — browsing the web, running prompts, building tables, producing memos — and leaves its outputs as structured canvas artifacts for downstream agents to build on. Critically, agents also validate each other’s work — reviewer personas check outputs before they’re passed downstream, catching reasoning errors before they have the chance to compound across a long execution chain.
Structured Handoffs
One of the core challenges in multi-agent systems is context degradation over time — as agents hand off to one another, information gets lost, summarized away, or misinterpreted. Spine Swarm addresses this at two levels.
First, the canvas itself maintains a persistent, structured record of all work — every block, every output, every artifact produced by every agent is visible and accessible to any agent that comes after it.
Second, agents leave explicit handoffs — structured summaries of what was done, what was found, and what remains — specifically designed to be consumed efficiently by the next agent in the chain. This isn’t a log or a dump of context. It’s a deliberate, agent-readable artifact that allows the system to keep building coherently over several hours without losing the thread.
Pause, Resume, and Human-in-the-Loop
For the GAIA and DeepSearchQA benchmark runs, human intervention was disabled entirely — agents ran independently from start to finish, with no human input. The results above reflect fully autonomous performance. But this is a deliberate configuration choice, not an architectural constraint.
Spine Swarm agents are not fire-and-forget. They are capable of waiting on upstream tasks, pausing execution mid-workflow, surfacing clarifying questions to a human, and resuming seamlessly once a dependency resolves or a response is received. The dependency graph and state management infrastructure handles all of this — tracking which agents are running, which are queued, which are waiting, and what conditions need to be met before execution continues. This design supports both fully autonomous runs and human-in-the-loop workflows — giving teams the ability to intervene, redirect, or approve outputs at any point in a long-running task.
3. Multi-Model Ensembling: The Right Model for Every Step
Most agent systems are built around a single model. The choice of model is made once, at the system level, and every task — regardless of its nature — is handled by that model. This is a reasonable default. It is also a ceiling.
Spine Swarm orchestrates across 300+ models, including the frontier versions of Claude, GPT, and Gemini. Each block type has a default model optimized for that task — but the system doesn’t stop there. When an agent’s confidence in a reasoning step is low, it doesn’t proceed on uncertain footing. Instead, it pulls perspective from one or two additional models before continuing, using disagreement between models as a signal that a step warrants deeper scrutiny.
For tasks where a single perspective is insufficient, the orchestrating agent can override block-level model settings entirely — spinning up an ensemble of frontier models running the same prompt in parallel as separate blocks, then consolidating their outputs through a synthesis prompt block. This isn’t just redundancy. Multiple models reasoning independently on the same problem surface different angles, catch different errors, and produce a consolidated output that is more robust than any single model could achieve alone.
For benchmarks like GAIA Level 3 and DeepSearchQA — where a single reasoning error anywhere in a long chain produces a wrong answer — this has a meaningful impact. The ensemble approach acts as a correction layer at the steps most likely to introduce error, and the dynamic model switching ensures that no single model’s blind spots propagate unchecked through a long execution chain. The result is a system that is not just as good as its best model — it is better.
The Bigger Picture: What This Means for AI Agents
Architecture Matters More Than Scale
The prevailing assumption in AI benchmarking is that performance is a function of the model. A better model gets a better score. The path to progress is a better model. Spine Swarm’s results challenge that assumption directly.
The models we used are the same frontier models available to every other system on these leaderboards. We didn’t win because we had access to a better model. We won because of how those models are orchestrated, what environment they operate in, and how they build on each other’s work. The architecture is the advantage.
This has a broader implication worth stating plainly: the era of single-model benchmarking is a poor proxy for real-world capability. Real-world tasks are long, messy, and multi-step. They require parallel exploration, sustained reasoning, and the ability to recover from uncertainty. No single model running in a loop — however capable — is optimally suited to all of them.
What we are building is a harness that gets more out of the models that already exist. And as the models themselves continue to improve, the harness compounds those gains rather than bottlenecking them.
The Canvas Paradigm Is the Future of Knowledge Work
The canvas wasn’t designed to win benchmarks. It was designed to reflect the way knowledge work actually happens — non-linear, iterative, and structured around the relationships between ideas rather than the contents of folders.
Knowledge workers don’t think in files. They think in structures — outlines that branch, research threads that fork, drafts that exist in parallel, sources that feed into multiple workstreams at once. The tools they use today — file systems, email threads, shared documents — impose a linear, hierarchical structure on work that is fundamentally not linear or hierarchical. The result is friction: context lost in handoffs, work siloed in folders, insights buried in files no one can find.
The canvas removes that friction. Work lives where it was created, in relationship to everything it connects to. A source feeds into multiple analyses. A research thread branches into parallel explorations. An output from one agent becomes the input to three others. The structure of the canvas mirrors the structure of the problem — and that turns out to be as valuable for agents as it is for humans.
This is why we believe the canvas paradigm is not just a better interface for AI agents — it is a better interface for knowledge work, period. The benchmark results are a proof point. The real opportunity is what happens when this paradigm is applied to the full spectrum of research, analysis, and decision-making that organizations run on every day.
Multi-Model Ensembling and Cross-Validation Is Inevitable
The AI industry has spent the last several years in a race to build the best single model. That race is not over — but it is becoming less relevant as the primary axis of competition.
The reason is straightforward: no single model is best at everything. Frontier models from different labs have different strengths, different blind spots, and different failure modes. A system that commits to one model inherits all of its weaknesses. A system that can dynamically select, ensemble, and cross-validate across models inherits the strengths of all of them.
This is not a novel idea in machine learning — ensembling has been a foundational technique in classical ML for decades. What’s new is that it is now practical at the agent level. The cost of inference has dropped far enough, and the tooling has matured far enough, that running multiple frontier models on the same reasoning step and consolidating their outputs is no longer prohibitive. It is, increasingly, the right default.
Spine Swarm’s benchmark results are an early demonstration of what this unlocks. When confidence is low, pull another perspective. When a task is high-stakes, run an ensemble. When models disagree, treat the disagreement as a signal — not a problem to paper over, but information about where the reasoning is genuinely uncertain.
As models continue to improve, ensembling and cross-validation will not become less important — they will become more important. The best systems will not be the ones that pick the best single model. They will be the ones that know how to use all of them.
Transparency Enables Trust at Scale
The benchmark results demonstrate capability. But the bigger question for any organization considering deploying AI agents in production is not whether they can perform — it is whether they can be trusted.
Most agent systems are black boxes. A task goes in, an answer comes out, and what happened in between is largely opaque. For low-stakes tasks, this is acceptable. For the kind of high-stakes research, analysis, and decision-making that organizations run on — the work that informs strategy, drives investment, and shapes policy — opacity is a non-starter.
The canvas changes this. Because every step of every task is executed on the canvas, every reasoning step, every source consulted, and every output produced is visible, auditable, and traceable. There is no gap between what the agent did and what a human can verify. If an agent made an error, you can find exactly where. If an agent produced a result you want to defend, you can show your work.
Trust at scale requires transparency at every step. The canvas makes that possible — and our benchmark runs offer a concrete demonstration of why it matters. By inspecting our agents’ work directly on the canvas, we were able to identify mislabeled and ambiguous questions in the GAIA dataset that would otherwise have been invisible. The transparency that makes Spine Swarm auditable in production is the same transparency that made our benchmark results more rigorous. That’s not a coincidence — it’s the point.
Supporting Evidence
Every step of every benchmark run is visible on the canvas. Here’s what that looks like in practice — and what we found along the way.
Some GAIA questions are void without the right approach
GAIA questions reference 2024. Many of those pages have since changed or disappeared. We instructed the system to search Web Archive when live pages came up empty — otherwise a significant number of questions would have been unanswerable. This is also why we ran Level 3 only.
- Eva Draconis has a personal website accessible from her YouTube page. What is the meaning of the only symbol in the top banner with a curved line that isn’t a circle? Answer without punctuation. Answer: War is not here this is a land of peace → canvas
Questions where the benchmark was wrong
These are the cases behind our corrected score of 76%. Our agents produced the right answer. The benchmark marked them wrong. Because every step is visible on the canvas, we could prove it.
Bills shorter than 42mm — the benchmark’s ground truth used
COUNTIFS(C1:C345, ">42")which counts bills longer than 42mm → canvasClaude Shannon question requiring navigation of a specific Slack thread from a historical context → canvas
The canvas in action on hard tasks
These are examples of Spine Swarm reasoning through genuinely complex multi-step research — the kind both benchmarks are designed to test.
GAIA: Harlequin shrimp / sea star — multi-step biological research across fragmented sources → canvas
DSQA: Nordic countries environmental tax + expenditure → Norway, Finland, Iceland → canvas
DSQA: South-Eastern Asia GDP growth 1965–1975 → Myanmar, Thailand → canvas
DSQA: UN data — internet usage, life expectancy, unemployment by world region → Central Asia, Western Asia → canvas
DSQA: NYC MTA subway delays + busiest stations → Times Sq-42 St, 34 St-Herald Sq, 14 St-Union Sq → canvas
We’re happy to open up the full dataset runs.
Next Steps: Experience Spine Swarms in Action
Spine Swarms is currently available in early access.
We currently have over 7,000 people on the waitlist. If you’re doing complex knowledge work and want to see what this looks like in practice — join the waitlist.
Appendix
Block Type Reference
1. AI Outputs — Focused, single-purpose content generated by AI in response to a prompt or upstream context.
Prompt — A direct LLM invocation. The foundational building block for any AI-driven step in a workflow.
List — Structured enumeration of items, options, or findings — useful for breaking down complex outputs into scannable form.
Table — Tabular output for structured comparison, ranking, or data organization.
Memo — A concise, audience-tailored report that distills research or analysis into a shareable narrative.
Deep Research — A long-form, multi-source research report generated through extended reasoning and web retrieval.
Image — AI-generated images from a text prompt.
2. Artifact Builders — AI-generated deliverables with production-ready formats, ready to share or deploy.
Slides — Fully formatted slide decks generated from canvas content.
Document — Word documents structured around research, analysis, or narrative content.
Excel — Spreadsheets with structured data, formulas, and formatting.
Landing Page — Marketing pages generated from a brief or existing content.
App — Functional interactive applications generated from a specification.
Prototype — UI/UX mockups for product and design workflows.
3. Data & Source Ingestion — Blocks that bring external information into the canvas as structured context for downstream agents.
Web Page — Fetches and parses a URL, making its content available to connected blocks.
Files — Uploads and ingests documents — PDFs, spreadsheets, text files — as structured canvas context.
YouTube Video — Imports and indexes the transcript of a video for use in downstream reasoning.
4. Agentic / Execution — Blocks that don’t just generate content — they act. These blocks can navigate interfaces, interact with live systems, and complete multi-step tasks autonomously.
- Browser Use — A fully autonomous agent that interacts with web applications and pages — clicking, form-filling, navigating, and extracting information from live environments.
5. User / Agent Annotation — Structured context written by agents to capture reasoning, plans, and handoffs at any point in a workflow.
- Notes — Used by agents to record their thinking, outline next steps, and leave explicit handoffs for downstream agents to review, consume, and build on. Also supports human annotation for injecting context or instructions directly into a workflow.